Music Auto Tagger - 基于音频指纹的智能音乐库整理工具
Music Auto Tagger - 让你的音乐库自动拥有完美标签
项目简介
Music Auto Tagger 是一个我开发的基于音频指纹和时长序列指纹的自动化音乐整理工具。它专为 NAS 和服务器环境设计,能够监控下载目录,自动识别音乐文件,补全元数据(包括歌词),并整理归档到你的音乐库中。
核心价值: 告别杂乱无章的音乐文件夹,让你的音乐库自动拥有完美的标签、封面和歌词。
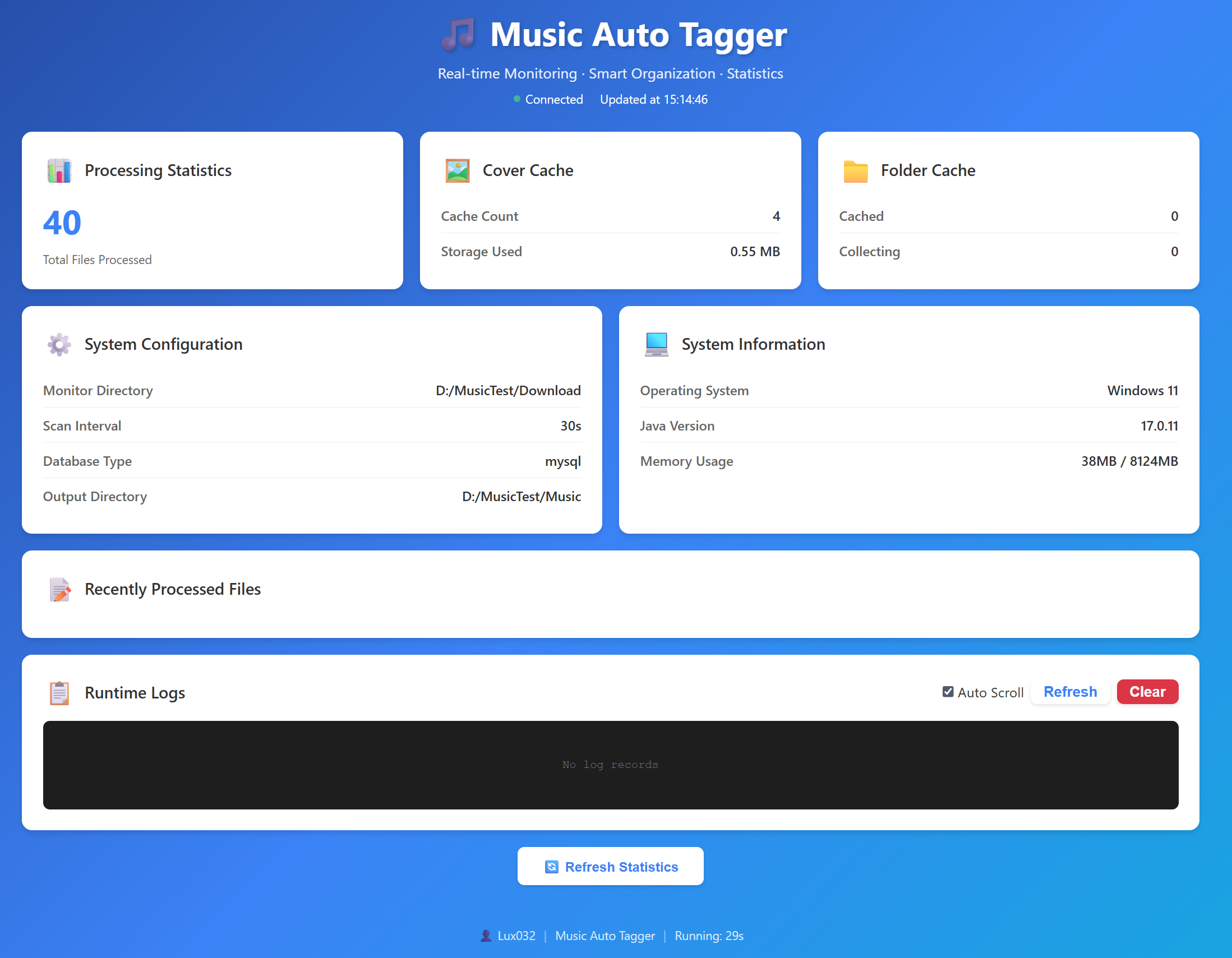
为什么开发这个项目?
作为一个音乐爱好者,我经常会下载各种音乐文件。但这些文件往往存在以下问题:
- 文件名乱码或不规范 (如
track01.mp3,未知艺术家 - 未知歌曲.mp3) - 缺少标签信息(艺术家、专辑、年份等)
- 没有封面图片
- 缺少歌词文件
手动整理这些文件既费时又容易出错。市面上虽然有一些音乐管理工具,但要么功能不全,要么不支持自动化运行,要么需要付费。因此我决定开发一个开源的、全自动的音乐整理工具。
核心特性
🎧 音频指纹识别
使用 Chromaprint (AcoustID) 技术,即使文件名是乱码也能精准识别歌曲。这是项目的核心功能之一。
📝 权威元数据源
数据源自 MusicBrainz 音乐数据库,自动补全:
- 标题 (Title)
- 艺术家 (Artist)
- 专辑 (Album)
- 年份 (Year)
- 作曲 (Composer)
- 作词 (Lyricist)
- 以及更多…
📜 自动同步歌词
集成 LrcLib 歌词服务,自动下载并嵌入同步歌词 (.lrc 格式),完美支持现代音乐播放器的歌词显示功能。
🖼️ 高清封面
自动从 Cover Art Archive 下载并内嵌高清专辑封面,让你的音乐库看起来更专业。
📁 智能整理
按照 艺术家/专辑/歌曲名 的结构自动重命名和归档文件,告别混乱的文件夹结构。
⚡ 智能扫描优化
这是我特别自豪的优化功能:
两级识别策略:
- 第一级: 快速扫描 - 基于现有标签和时长序列指纹匹配,90% 准确率即可通过
- 第二级: 指纹识别 - 仅在快速扫描失败时启用完整的音频指纹识别
文件夹级缓存: 同一专辑的后续文件直接使用缓存结果,跳过所有扫描过程
性能提升: 处理一张 16 首的专辑,仅需 1 次完整扫描 + 15 次缓存查询,大幅提升处理速度
🤖 无人值守运行
配合 qBittorrent/Transmission 等下载工具使用,下载完成后自动处理,完全无需人工干预。
💾 灵活的持久化方案
支持两种模式:
- 文本模式 (默认): 使用 CSV 文件记录,零配置,开箱即用
- MySQL 模式: 支持外部数据库,适合海量文件场景
📊 Web 监控面板
内置实时监控面板 (基于 Jetty),可以:
- 查看实时统计信息和处理进度
- 浏览最近处理的文件详情
- 实时查看系统运行日志
- 查看系统配置和状态
🌐 多语言支持
支持中文和英文界面,可通过配置文件轻松切换。
技术架构
技术栈
- 语言: Java 17+
- 构建工具: Maven
- 音频处理: JAudioTagger
- HTTP 客户端: Apache HttpClient 5
- JSON 解析: Jackson + Gson
- 日志框架: SLF4J
- Web 服务器: Jetty (嵌入式)
- 数据库: MySQL (可选) + HikariCP 连接池
- 容器化: Docker
核心服务模块
项目采用模块化设计,主要包含以下服务:
- AudioFingerprintService - 音频指纹识别服务
- MusicBrainzClient - MusicBrainz API 客户端
- LyricsService - 歌词下载服务
- CoverArtService - 封面下载服务
- TagWriterService - 标签写入服务
- FileMonitorService - 文件监控服务
- DatabaseService - 数据库持久化服务
- QuickScanService - 快速扫描服务
- DurationSequenceService - 时长序列指纹服务
- FolderAlbumCache - 文件夹级缓存服务
- WebServer - Web 监控面板服务
设计亮点
1. 两级识别策略
为了在准确性和性能之间取得平衡,我设计了两级识别策略:
- 第一级: 快速扫描 - 基于现有标签和时长序列指纹匹配,90% 准确率即可通过
- 第二级: 完整指纹识别 - 仅在快速扫描失败时启用
这样可以让大部分已经有基本标签的文件快速通过,只对真正需要的文件进行完整的指纹识别。
2. 文件夹级缓存
当识别出一个文件属于某张专辑后,同一文件夹内的其他文件会直接使用这个缓存结果,避免重复识别。这大大提升了批量处理同一专辑文件的效率。
3. 优雅的生命周期管理
使用统一的生命周期管理器管理所有服务的启动、运行和关闭,确保资源的正确初始化和清理,避免内存泄漏。
4. 智能失败处理
对于识别失败的文件,系统会:
- 自动重试指定次数 (可配置)
- 将完全失败的文件移动到
failed_files目录 - 将部分识别成功(有标签或封面但指纹失败)的文件移动到
partial_files目录
这样方便用户后续手动处理这些特殊文件。
快速开始
Docker 部署 (推荐)
下载配置文件模板并重命名:
wget https://github.com/lux032/MusicAutoTagger/raw/main/config.properties.example mv config.properties.example config.properties申请免费的 AcoustID API Key:
访问 https://acoustid.org/new-application创建
docker-compose.yml:version: '3.8' services: music-tagger: image: ghcr.io/lux032/musicautotagger:latest container_name: music-tagger ports: - "8080:8080" volumes: - /path/to/downloads:/music - /path/to/music_library:/app/tagged_music - ./config.properties:/app/config.properties - /path/to/failed:/app/failed_files - /path/to/cover_cache:/app/.cover_cache - /path/to/logs:/app/logs restart: unless-stopped启动服务:
docker-compose up -d访问监控面板:
打开浏览器访问http://localhost:8080
本地运行
# 1. 编译
mvn clean package
# 2. 配置
cp config.properties.example config.properties
# 编辑 config.properties 填入 API Key
# 3. 运行
java -jar target/MusicDemo-1.0-SNAPSHOT.jar使用建议
为了获得最佳的整理效果,我建议:
将同一张专辑的音频文件放入一个单独的文件夹中
✅ 推荐:
/Downloads/Jay_Chou_Fantasy/(包含范特西整张专辑)/Downloads/Adele_21/(包含 21 整张专辑)
❌ 不推荐:
/Downloads/Music/(混合了数百首不同专辑的歌曲)
原因: 当文件被隔离在独立文件夹时,程序能结合上下文更好地判断它们属于同一张专辑,避免将专辑歌曲误匹配到精选集版本。
适用场景
这个工具特别适合:
- 🏠 家庭 NAS 用户: 在 Synology、QNAP、Unraid 等 NAS 上自动整理音乐库
- 🎵 音乐爱好者: 拥有大量音乐文件需要整理
- 🤖 自动化爱好者: 配合下载工具实现完全自动化的音乐下载和整理流程
- 📚 媒体服务器用户: 为 Plex、Jellyfin、Emby 等媒体服务器准备规范的音乐库
开发心得
在开发这个项目的过程中,我遇到了一些有趣的挑战:
1. 音乐识别的准确性
音乐发行形式非常复杂,同一首歌可能存在:
- 单曲版本 (Single)
- 专辑版本 (Album)
- 精选集版本 (Best Of)
- 豪华版 (Deluxe Edition)
- 不同地区版本
如何准确匹配到正确的版本是一个挑战。我通过结合时长序列指纹和文件夹上下文信息,大大提高了匹配准确度。
2. 性能优化
最初的版本每个文件都需要完整的指纹识别,处理速度很慢。通过引入两级识别策略和文件夹级缓存,性能提升了约 **80%**。
3. 网络稳定性
MusicBrainz 和 LrcLib 等外部 API 可能会出现网络波动。我实现了:
- 智能重试机制
- HTTP 代理支持
- 优雅的错误处理
- 失败文件隔离
4. 跨平台兼容性
为了让工具能在 Windows、Linux、macOS 和各种 NAS 系统上运行,我做了大量的兼容性测试,最终选择了 Docker 作为主要部署方式。
总结
Music Auto Tagger 是我业余时间开发的一个实用工具,它解决了我自己的实际需求,也希望能帮助到其他有相同需求的音乐爱好者。
项目已在 GitHub 开源,采用 MIT 许可证,欢迎大家使用、提 Issue 和贡献代码!
如果这个项目对你有帮助,欢迎给个 ⭐ Star!
相关链接
- 🔗 GitHub 仓库: https://github.com/lux032/MusicAutoTagger
- 📖 完整文档: README.md
- 🐳 Docker 镜像: ghcr.io/lux032/musicautotagger:latest
- 💬 Issue 反馈: https://github.com/lux032/MusicAutoTagger/issues
鸣谢
感谢以下开源项目和服务:
- MusicBrainz - 音乐元数据服务
- AcoustID - 音频指纹识别服务
- LrcLib - 歌词服务
- Cover Art Archive - 封面图片服务
- JAudioTagger - 音频标签库
本文介绍的项目完全开源免费,遵循 MIT 许可证




